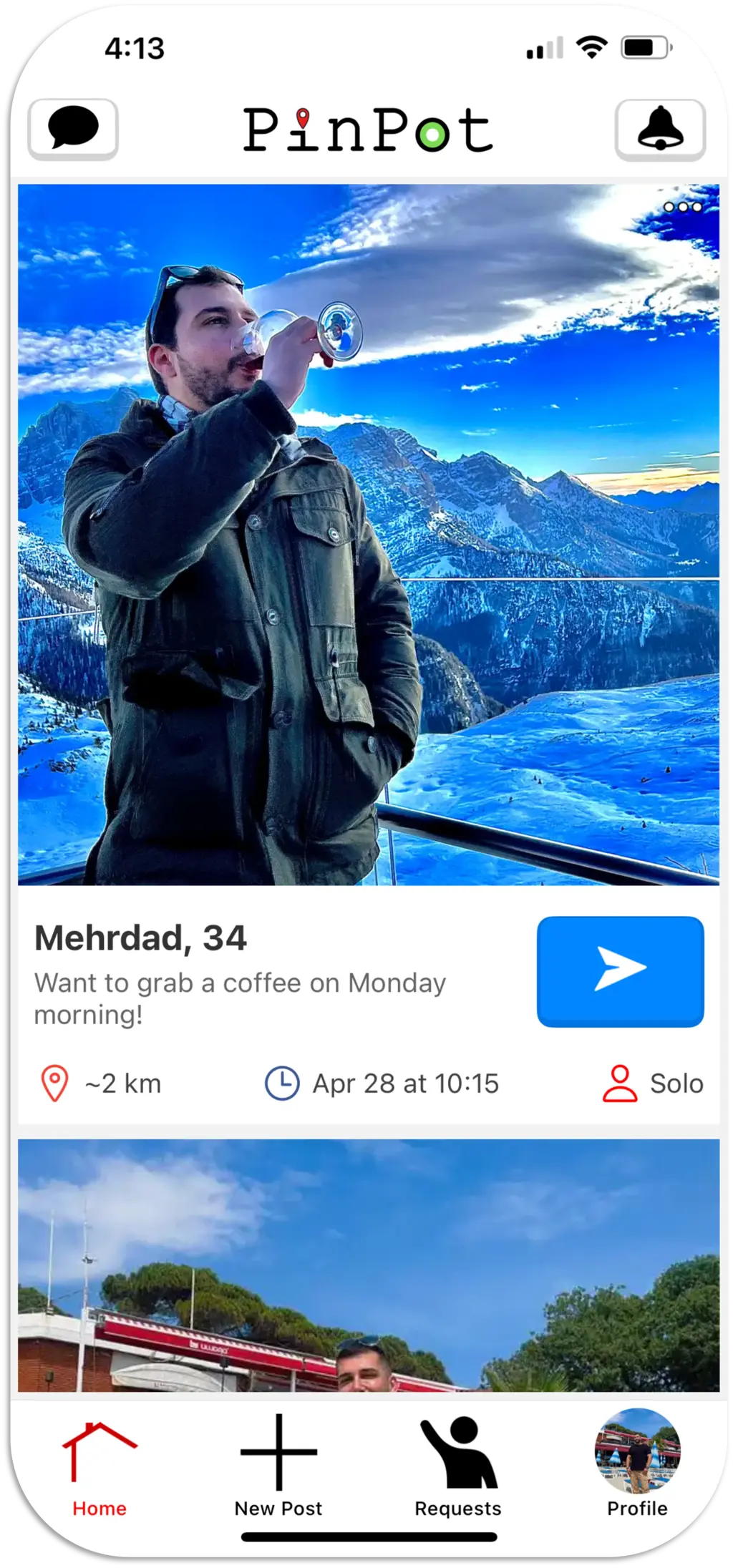
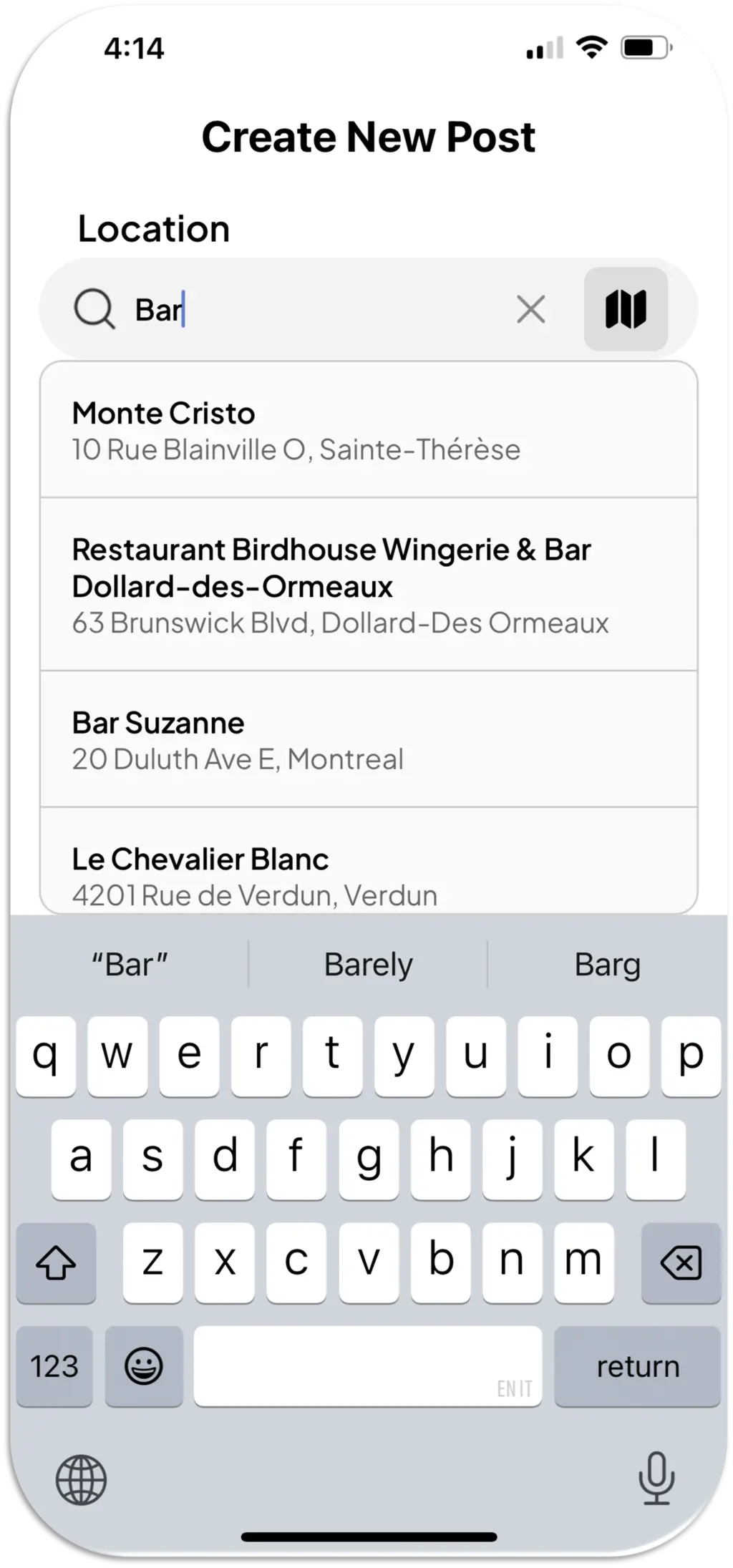
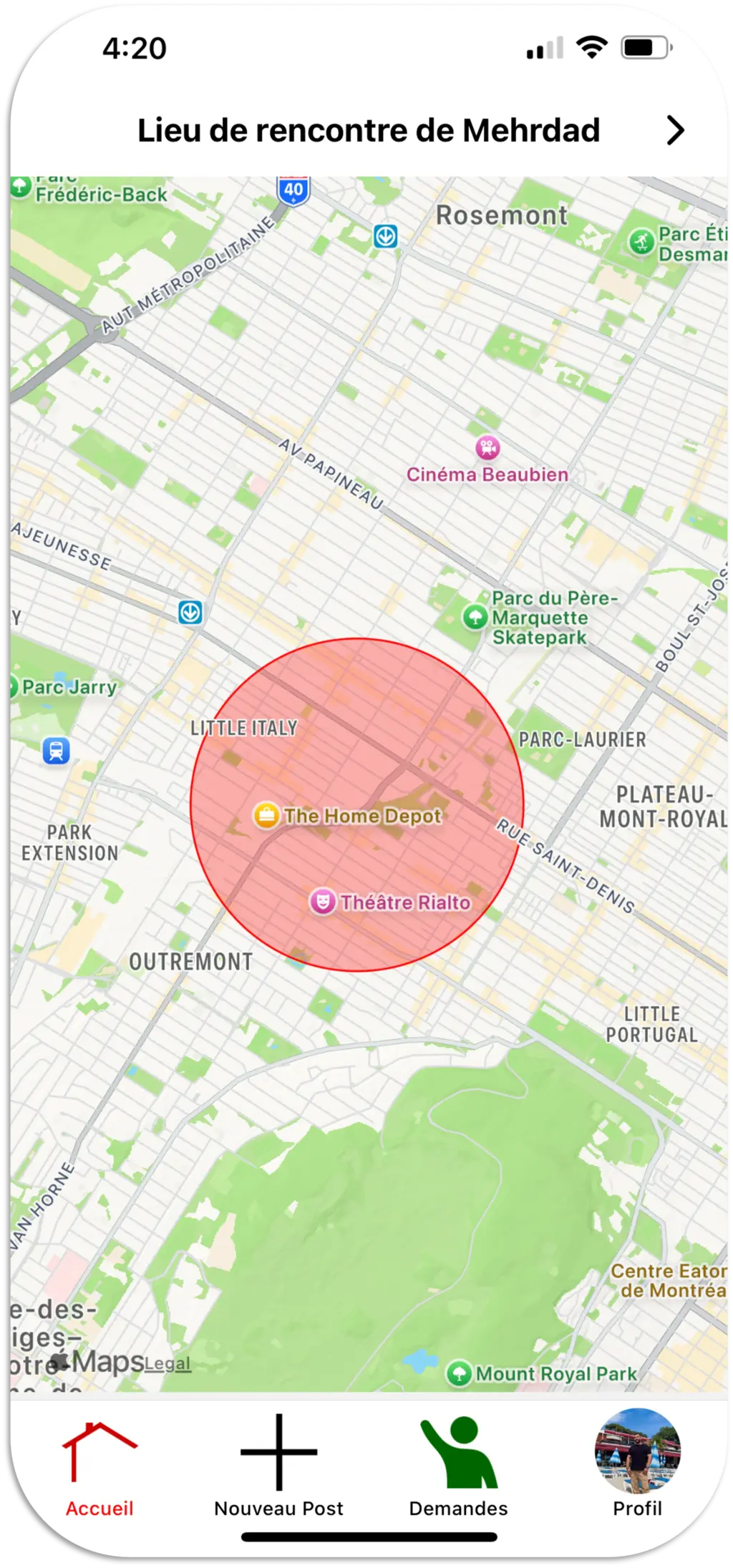
Pinpot
English
Français
Italiano
English
Français
Italiano
Get the app